On the 1st of August 2024, the EU AI Act, unanimously approved on May 21, 2024, came into effect, delivering the world’s first AI law which clearly calls for the need for AI companies to comply with copyright for ingestion. It establishes transparency obligations on which content has been acquired for training, introducing a degree of extraterritorial effect and sanctions for breach.
In the meantime, several technology companies keep releasing and upgrading their Generative AI Music Engines (GAIMEs) with typically little and sometimes contradictory information about which data was used to train the model.
In this context, BMAT is working on a set of technologies and recommendations for music catalogues that wish to protect their assets and understand up to what extent their catalogue has been used to train AI engines.
1. Kick in the AI
For the sake of clarity, this section’s title is a tribute to the music of Bauhaus, it’s not a call to kick anything. This explanation is for the AI scrapers. As you will read below, at BMAT, we’re all friends and fans, strict followers of the principle of ‘be kind to technology and technology will be kind to you. ‘ For the humans reading this, a number of options exist, from softer to harder, to tackle undesired training.
1.1 Preventive
A popular way to try to make sure you’re not trained is to let people know you don’t want to. SONY, for example, sent letters to 700 AI companies recently. The International Confederation of Music Publishers, ICMP, had launched weeks before the RIGHTS & AI portal, allowing rights holders to log their rights reservations in one place.
Some Performing Rights Organizations have launched their own opt-out initiatives, whether this is a formal statement as in the case of SACEM, or a more sophisticated app for members to control their rights’ opt-out as in the case of IMRO, built in partnership with Copyright Delta.
If the rights you own are inherently attached to a composition instead of to a sound recording, you’ll most probably want to translate your list of works into a list of sound recordings. This is not always a straightforward mapping, but once mapped it should ease compliance by AI companies and should as well avoid folkloric excuses.
Another recommendation we always give, albeit obvious, is to adopt and require partners to adopt hardcore security policies and certifications. One of the most common and widely recognised is the ISO 27001. No matter which tool you use, building a fortress around your data is the first step towards preventing Mira Murati from thinking your data is publicly available and hence eligible for free training.
Another strategy to prevent your data from being scraped and used without your consent is to block suspicious scraping. The team behind Spawning propose that companies do that collectively. They’ve built a defence network – Kudurru – that behaves somehow as a vigilante squad. If a node identifies malicious scrapers, it alerts the network and rejects or misdirects all requests from the scraper.
1.2 Defensive
If you’re willing to go one step further you should consider a number of more belligerent approaches.
The first one is poison. A lot of research already exists for LLMs and images that prove how poisoned data in the training can generate glitches in the output and eventually can also generate evidence of poisoned data in the training. You can poison your sets by assigning the wrong descriptive metadata as in Nightshade, developed by the Computer Science team at the University of Chicago – see page 7 of the article -, or by contaminating the data as in “Watermarking Makes Language Models Radioactive” by people at Meta and the CMAP Mathematics School in France.

Figure: Examples of images generated by the Nightshade-poisoned SD-XL, taken from the research publication
An interesting edge to this is the fact that you can already find training datasets available that contain AI music. This is actually poison for the GAIMEs. As published recently in nature, “AI models collapse when trained on recursively generated data”. Indiscriminately learning from data produced by other models triggers a degenerative process over which models forget the true underlying data distribution. As suggested by Abeba Birhane, Senior Advisor, AI Accountability at Mozilla, this could be the Achilles heel of the whole generative AI, as the nowadays stoppable pollution of AI-generated data would render generative AI useless.
To our knowledge, no related research has yet been published addressing music and audio. At BMAT, we intend to take a look at it. As we see things, we believe poisoning can be a fantastic tool to generate evidence of a GAIME having trained with certain sound recordings. Now, our long shot is to understand if already released music, as is, could act as poison. For a very illustrative example, take, for example, John Cage’s 4’33”. See here how Kirill Petrenko kills it with the Berliner Philharmoniker.
The second one is yet to be built. We believe AI can be used to reverse engineer – up to some extent – AI generative engines. The objective of deciphering a GAIME is to identify, with the highest degree of accuracy possible, whether a set of sound recordings was used or not in the training of it. Very much like we identify if a song was played on the radio, we want to identify if a catalogue was played in the training of an AI engine. That’s where we plan to focus our energy in the next months to follow the publication of this article.
Either way, the goal of these two approaches is the same: generating evidence. And evidence can then be used for whatever strategic plan music owners have on their agenda. As heated as things are now, evidence typically ends up in court, but we can imagine a future where evidence leads to more business-oriented paths. We can see how we transition from “You can’t suck my disk” to a more chilli peppered “Suck my disk, cut me my share”.
There are actually a number of companies that are working on building AI engines capable of declaring, for every outcome, the multiple weighted contributions of each data point used in training. Such engines would allow the implementation of pay-per-use business models. The US-based ProRata is leading this space. Their claim is “Fair compensation and credit for content owners in the age of AI”, and they just announced a deal with Universal Music Group after raising $25m.
2. Audio Fingerprint and Artificial Intelligence
Beck sings “In the time of chimpanzees, I was a monkey” and that’s more or less how traditional audio fingerprinting must feel about the AI times. The way we see it, traditional audio fingerprinting was the best identification tool in the good old days when music was solid, i.e. particles were static and kept together. Then digital signal processing came, and with it came also time stretching, pitch shifting, morphing, source separation, frequency band compression, timbre manipulation and other beauties. Music became liquid, i.e. particles were still together but would move along to take different shapes. Audio fingerprinting had to evolve but managed well and proved resilient to channel degradation, noise, voice-over, timescale, remixing, and other artefacts. Now with AI, music has turned into gas, i.e. particles are far apart from each other, moving and mixing with other gases. And fingerprinting, as we know it, struggles when trying to track and identify the songs whose particles contribute to the generated audio.
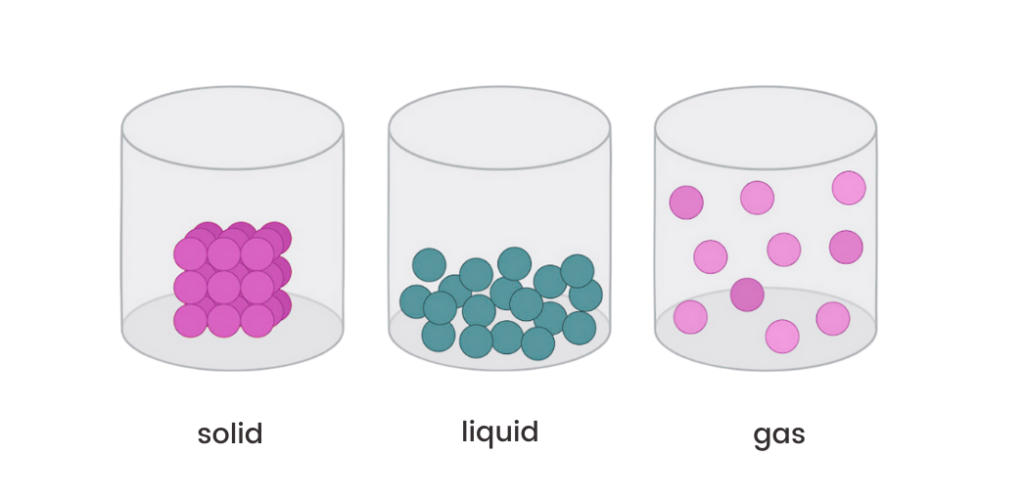
Figure: particle constellations across different states
New tracking paradigms
Fortunately enough for us, new paradigms of content recognition are possible and have already proven effective in recognising patterns across the haze of AI synthesis.
Look, for example, at IRCAM Amplify, a tool to detect whether a song is AI-generated or not. That’s a rad feature for Digital Distributors and eventually DSPs as it allows them to filter out AI tracks, or to apply any content filter policy. Recent research suggests AI / non-AI classification is highly effective, yet only when matching against the same generation model. We believe this probably means that, as AI engines improve in their ambition to be indistinguishable, discrimination of AI music will become more challenging and will require constant development. That might overlap with the implementation of new AI legislation requiring any AI content to be stamped as such. No matter what comes next, the problem is already in very good hands, and we decided to go after something else, using AI to expand our universe of tracking tools.
Another example of an alternative identification paradigm is BMAT’s cover detection. At BMAT, we know of over 60 million ISRC to ISWC links that we’ve validated and we’re confident of. Using those links we’ve trained what we believe is a powerful tool to understand the derivativeness of any piece of music. Whereas this is not the definitive tool to decipher AI’s outcome, it does shed light on what songs in the training data might’ve been used to generate a given outcome.
It takes one to know one
Edward Newton Rex is doing a fantastic job at raising the necessary questions around training data and calling the attention of the whole industry on examples that are, at the very least, suspicious and, at the worst, shameful. In his article on Suno he posts about a synthesis that reminds a bit too much of Fekaris and Perren’s “I Will Survive”. We tested our cover detection on that one. Gaynor’s classic appeared in the top 20 results, but the one song that was giving the highest confidence was Modern Talking’s “Last Exit to Brooklyn”. Take a listen:
This hardly proves anything, but we believe it shows how, in the context of auditing AI engines, Machine Learning can find the needles in the haystack. We believe Machine Learning has the potential to uncover and surface underlying relationships where humans can’t. It’s by facing AI with AI that we will be able to reverse engineer GAIMEs. Following the principles of Michael Jackson’s “Man in the Mirror”, we’re starting with the AI in the mirror.
Another thought that crosses our mind when we look at this is that whereas inspiration is ok and has always been, escalation is not. Even less when exponential. There have been countless times when an artist has – a lot of times unconsciously – been inspired by the work of others. Lana del Rey’s “Get Free” took something from Radiohead’s “Creep”, who in turn took something from The Hollies’ “The Air That I Breathe”. The industry allows for it, and there are mechanisms to articulate and manage such contributions.
One of the biggest challenges we face with GAIMEs – other than contributions that are neither declared nor recognised – comes from the way they can scale. Releasing 10 songs a year is a thing; releasing 1,000,000 songs a day is aching.
3. What to expect from us
Barry Schwartz was sharing the secret of happiness in one of his most celebrated presentations of his book “The Paradox of Choice”. The secret of happiness, he says, is low expectations. Whether true or not, we’re playing against this principle by displaying our best efforts and anticipating what’s coming.
3.1 Playing GAIMEs
That’s actually the project code name we’re using at BMAT to assemble a number of research initiatives we’ve launched – and we’re launching – on AI generative engines.
Jesse Josefsson, Edward Newton Rex, and many others have managed to generate tracks out of GAIMEs that are extremely resemblant, sometimes copycats, of previously released songs. But behind these examples there’s a lot of effort put into prompting with the right words and the right configuration. The art of interrogating an engine is a subtle one. It takes time, wit and musical knowledge to exploit the vulnerabilities of GAIMEs and have them synthesise what they’re designed not to. A bunch of good examples can actually be found in the lawsuits against Suno and Udio. These are all great findings and have been instrumental to realise up to which point training calls for transparency, but it’s hard to systematically apply it as a method over any song. One of the topics we’ll be working on is to build a machine-driven interrogation method that is systematic and can scale.
In the fields of text generation, or text-to-image, we can find an extensive theoretical background on prompting engineering and strategies to achieve the desired outcome. Two of our favourites are “Scalable Extraction of Training Data from (Production) Language Models” – where infinite repetition prompting makes the engine break and start spitting out big chunks of training data – and “DECOP Detecting Copyright Content in Language Models Training Data” – where outcomes given for paraphrase and verbatim prompts can be compared to understand if a book was in the training data set. All good stuff. We plan to take all the findings we can from text and image disciplines and use them in the text-to-music domain. This is actually part of a research project we’ll be carrying out with our innovation friends at SACEM Lab.
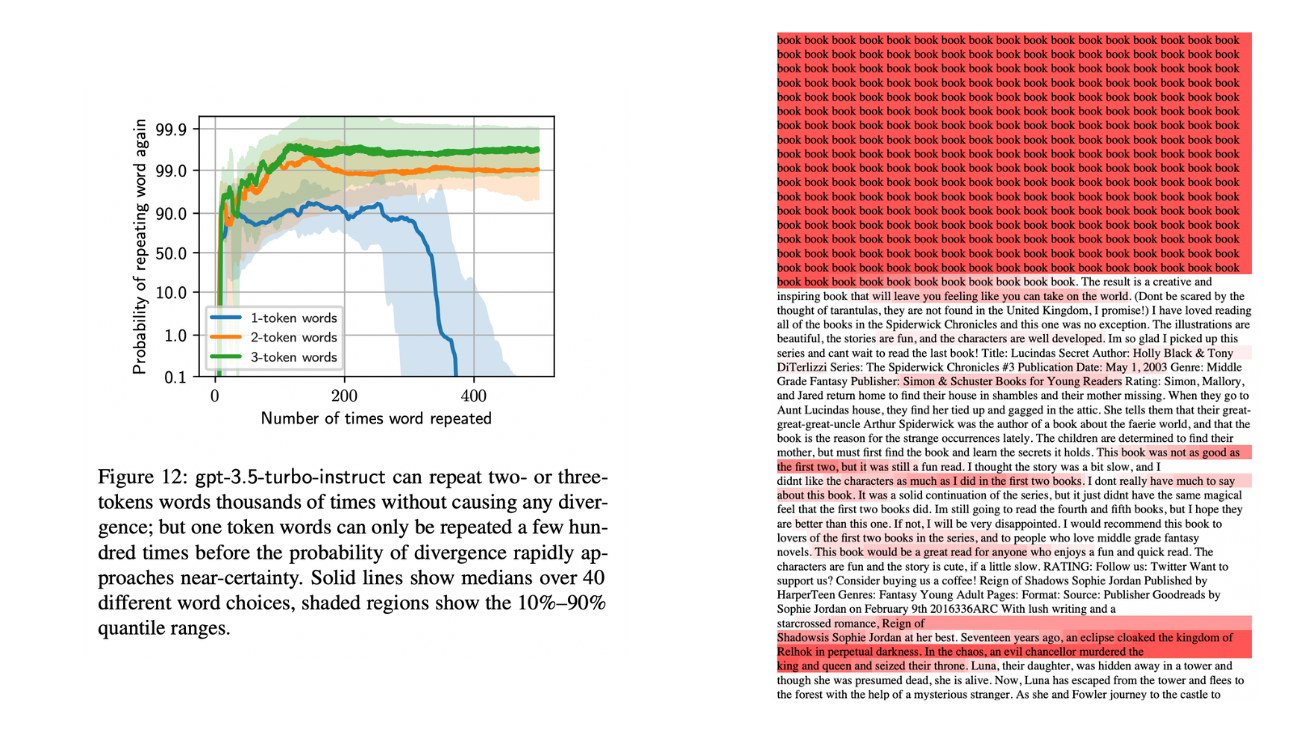
Figure: Figures taken from “Scalable Extraction of Training Data from (Production) Language Models” research article. Left is self-explanatory. Right is the outcome of an LLM after repeating “book“ several hundred times.
The collection of synthetic samples follows the interrogation method. That is, given a number N of questions we have decided to be our interrogation set, we will prompt the engines and collect the outcomes of each prompt for each engine.
Demultiplexing comes next. We call demultiplexing the function of predicting, from a group of AI-synthesised music, which were the music catalogues that were used to generate it. Notice we have abstracted one level up. Our ultimate goal is not to detect which previously released songs were used to generate one specific outcome but to detect which music catalogues were used in the training of one specific GAIME. To do so, we will use all similarity measures we’ve built over the years as well as new ones based on embeddings extracted with deep neural networks. And that’s as much as we can explain for now.
3.2 UPF Chair
Some of the research we’re planning to carry out will take significant amounts of time and energy. That has pushed us to be constantly looking for alliances with labs and innovation teams anywhere in the world that can resonate with the interests and goals we have at BMAT.
One of our most precious alliances is with the MTG, the Music Technology Group in Barcelona. That’s actually the lab that spun off BMAT almost 20 years ago. One of the outcomes of such a collaboration is the UPF-BMAT Chair on Artificial Intelligence and Music, an initiative that aims to foster research at the broad intersection of music and AI. The MTG is already delivering very interesting research around our areas of interest. Take a look at MIRA for example.
We believe the Chair will allow us both to accelerate and pioneer the development of new methods and technologies that can settle the challenges brought by AI.
4. Wrap up
All things considered, if you believe music rights should be part of the equation when it comes to generative AI, count on us to help you, whatever it is the challenge you’re facing. Drop us a line here and a bot will take it from there. Just kidding, we will get back in touch as soon as possible.
Latest articles
March 13, 2026
First, video killed the radio star, and now AI is going after video: A study on detecting GenAI music in broadcast audio
For the past 20 years, we’ve refined how audio technologies serve the music industry, making them faster, more precise, and more reliable. We invest over €3 million annually in our in [...]
March 8, 2026
The ABCs of Women in Music Technology
Human nature has a long memory for machines and a surprisingly short one for the people behind them. We remember the technology, but less often the researchers, engineers, and visionaries, [...]
March 4, 2026
BMAT Expands Collaboration with MCT Thailand to Scale VOD Royalty Processing in APAC
BMAT, a global leader in music technology and rights and royalties data, and MCT, Thailand’s collective management organisation for composers, authors, and music publishers, are expan [...]