For the past 20 years, we’ve refined how audio technologies serve the music industry, making them faster, more precise, and more reliable. We invest over €3 million annually in our in-house R&D department, and sharing that work is part of how we show what’s coming next.
A new paper from the UPF-BMAT Chair on AI and Music has been accepted to ICASSP 2026, which is one of the most prestigious international conferences dedicated to the intersection of signal processing, AI, and audio.
The study centres on AI-generated music detection in broadcast monitoring and compares it to detection performance on streaming platforms.
Gen AI music is now everywhere
It’s no secret that GenAI music has aggressively entered the chat. According to recent data, around 50,000 fully AI-generated tracks are believed to be uploaded daily on some streaming platforms, accounting for roughly one-third of new uploads.
Little published research currently quantifies the share of GenAI music in broadcast programming. The gap reflects measurement challenges, not confirmed absence. In other words, we all know it’s there.
As AI music generators advance, their output can be difficult to distinguish from human composition, at least for some. Call us optimistic, but we think it’s not because of how good they are, but because GenAI tracks are still too new to be fully registered in the collective listening consciousness.
When detecting AI-generated music on streaming environments, audio is clean, full-length, and foregrounded. Under these conditions, a CNN baseline achieved 99.97% accuracy on its held-out test set, while SpectTTTra models reached around 93% F1. For non-technical readers, the following paragraph explains how to make sense of that.
How these machines “listen”
A CNN, or Convolutional Neural Network, not the TV station, works as a pattern recogniser. It analyses spectrograms, visual representations of sound, and learns to detect statistical cues that separate human from AI-generated music. It performs particularly well when the signal is clear and uninterrupted.
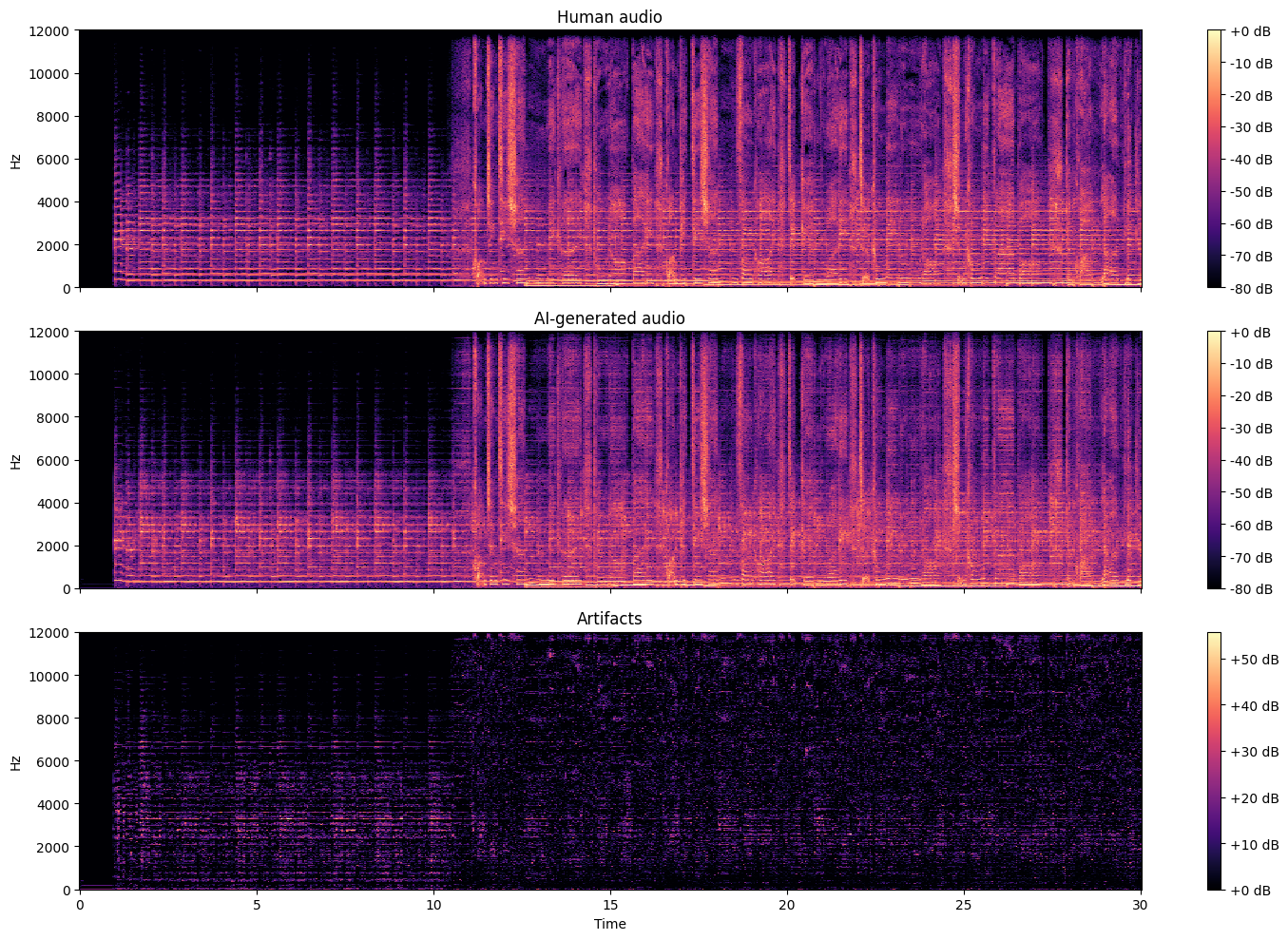
Illustration of the types of artifacts that generative models tend to create and that the CNNs learn to detect. Top, the spectrogram of a human song; center, an AI-generated version of the same song; and bottom, the artifacts produced by the model.
SpectTTTra models take a broader view. Rather than focusing only on local audio textures, they analyse how musical elements evolve across time and frequency. They pay attention to structure, continuity, rhythm, the things that make music feel coherent rather than merely audible.
In clean streaming conditions, both approaches perform strongly, though they rely on different aspects of the signal.
Broadcast replays by different rules
In broadcast, music appears briefly and often beneath speech. It shares space with transmission artefacts and the general messiness of live programming. Duration shortens, signal-to-noise ratios fluctuate, and musical context fragments.
Older State of TV Music Usage reports we compiled reflect this reality: music in television is present across programming but rarely dominant. Outside of music programmes, and apparently true crime and documentaries, it tends to live in the background and is mostly absent from the news.
Building a broadcast-native dataset
To evaluate GenAI music detection under these conditions, the study introduces AI-OpenBMAT, a dataset built specifically for broadcast monitoring.
AI-OpenBMAT contains 3,294 one-minute excerpts structured to reflect real television segment patterns and loudness relations. Human production tracks are paired with stylistically matched continuations generated using Suno v3.5 and mixed according to broadcast SNR statistics derived from annotated TV audio.
Or put differently, this is not clean audio with noise sprinkled on top but rather broadcast reality.
What we learned after testing under real conditions
As a recap, AI-Generated music detection performance was evaluated using two model families: a CNN baseline and advanced SpectTTTra architectures. They were tested across speech masking, short music duration, and full programme mixtures.
The results show a clear shift in detection performance between streaming and broadcast conditions. As speech becomes more dominant and music excerpts shorten, detection performance declines.
In full broadcast conditions, the best-performing SpectTTTra model reaches an overall F1 score of 61.1%, while the CNN baseline falls to 27.6%.
In streaming environments, by contrast, the same model family performs above 90% F1 under clean, foreground conditions, underscoring the gap between controlled audio and real broadcast mixtures.
Within broadcast specifically, detection remains strongest when music is foregrounded and weakest when it sits in the background.
What this means for Gen AI music monitoring
The implication is contextual rather than technological. Speech masking and short music excerpts are not anomalies in broadcast audio, but structural traits of the broadcast medium itself.
AI-OpenBMAT provides a benchmark aligned with that reality, supporting detection systems designed for monitoring environments rather than clean-track assumptions.
In other words, detection needs to learn to listen better where music is not the loudest voice in the room.
More research is always underway to advance how we detect musical works in any context, mixing and variation. We’ll continue sharing what we discover, so keep an eye out.
Latest articles
March 8, 2026
The ABCs of Women in Music Technology
Human nature has a long memory for machines and a surprisingly short one for the people behind them. We remember the technology, but less often the researchers, engineers, and visionaries, [...]
March 4, 2026
BMAT Expands Collaboration with MCT Thailand to Scale VOD Royalty Processing in APAC
BMAT, a global leader in music technology and rights and royalties data, and MCT, Thailand’s collective management organisation for composers, authors, and music publishers, are expan [...]
February 23, 2026
The party we weren’t ready for until now: BMAT turned 20
On an otherwise uneventful Barcelona evening in January 2026, more than 330 people filled La Paloma, a ballroom older than most tech companies and far more accustomed to sardanes and waltze [...]